At work there are machines I'd like to access from home using Windows networking (Samba servers mostly), but the catch is that the work firewall is blocking NetBIOS traffic (an awfully good idea). My home network uses a FreeBSD box for NAT (Network Address Translation). Here's a diagram of what we're talking about.
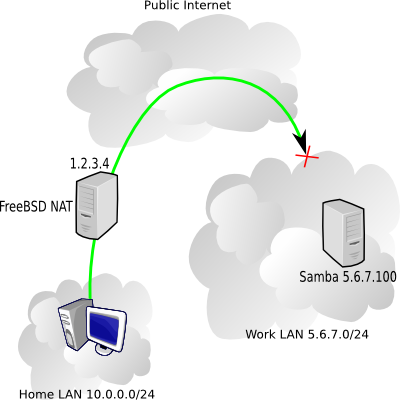
In the picture above, my home NAT box has the public IP 1.2.3.4, the internal home network is 10.0.0.0/24, and I'm trying to reach a work server 5.6.7.100 on the 5.6.7.0/24 network.
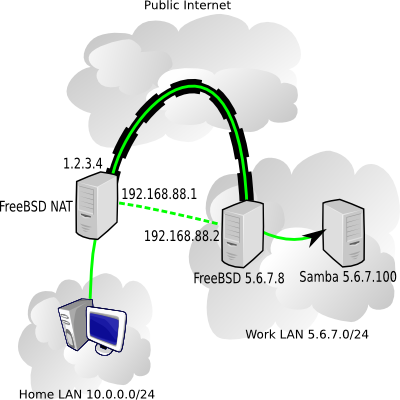
Fortunately, I have a FreeBSD box at work, with an address 5.6.7.8, and it's fairly easy to setup a simple OpenVPN tunnel between 1.2.3.4 and 5.6.7.8, and route NetBIOS traffic over that.
OpenVPN will make it appear as if the two machines have a point-to-point network connection, when in reality the traffic is passing encrypted over the public internet. We need to pull a couple IP numbers out of our hat to use for the VPN endpoints - I'll use 192.168.88.1 for the home machine and 192.168.88.2 for the work machine.
Settting up OpenVPN
On each box install the security/openvpn port. After that's done, on one machine, go to /usr/local/etc/openvpn and run:
openvpn --genkey --secret mykey
Copy the mykey file you just generated over to the other box's /usr/local/etc/openvpn directory. The two OpenVPN endpoints will used that shared key to authenticate each other.
On the 1.2.3.4 machine, create a /usr/local/etc/openvpn/openvpn.conf file containing:
remote 5.6.7.8
dev tun0
ifconfig 192.168.88.1 192.168.88.2
secret mykey
On the 5.6.7.8 machine, create a /usr/local/etc/openvpn/openvpn.conf file containing:
remote 1.2.3.4
dev tun0
ifconfig 192.168.88.2 192.168.88.1
secret mykey
(note that the ifconfig line swapped the IPs compared to the other machine's config)
Throw an openvpn_enable="YES" in each machine's /etc/rc.conf, and start the daemons: /usr/local/etc/rc.d/openvpn start
If necessary, allow OpenVPN traffic through your firewall, for the 1.2.3.4 box it might look something like:
pass in on $ext_if inet proto udp from 5.6.7.8 to $ext_if port 1194
pass on tun0
If this works, you should be able to sit at the 1.2.3.4 box and ping 192.168.88.2 and get a response. On the 5.6.7.8 box, running tcpdump -n -i tun0 should show the ICMP packets reaching the machine.
Routing specific traffic
I don't want to route all my traffic going to the 5.6.7.0/24 network through the VPN, I just want the NetBIOS stuff so I'll setup a split tunnel. PF makes it pretty easy to redirect network traffic through the VPN, in fact, I ended up doing a double-NAT, one on each end of the tunnel.
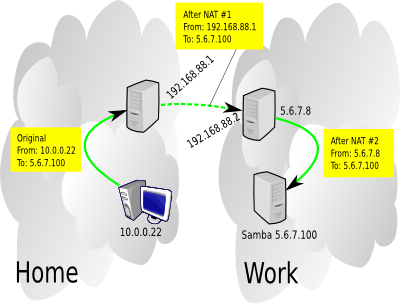
So when the home workstation contacts the Samba server, the Samba server sees the traffic as coming from the 5.6.7.8 box, and the 5.6.7.8 box saw the traffic as coming from the home FreeBSD NAT machine. So interestingly, neither of the work machines needs to have any clue about the home network. The PF state tables take care of reversing everything when the Samba server responds.
On the home 1.2.3.4 machine, these lines are added in the appropriate places to /etc/pf.conf:
int_if="eth1"
internal_net="10.0.0.0/24"
work_net="5.6.7.0/24"
.
.
nat on tun0 from $internal_net to any -> (tun0)
.
.
pass in on $int_if route-to tun0 proto tcp from any to $work_net port {139, 445} flags S/SA modulate state
That last line is the key to the whole thing, it's responsible for diverting the traffic we want to go through the VPN instead of over the public internet. If you want to secure additional protocols, just add similar lines.
The PF config on the work 5.6.7.8 machine is simpler, just
nat on $ext_if from 192.168.88.1 to any -> 5.6.7.8
To perform that 2nd NATting, making VPN traffic seem like it came from the work box.
Lastly, both machine need gateway_enable="YES" in /etc/rc.conf. A home NAT box probably already has that though.
There's a lot more that OpenVPN can do, we barely scratched the surface with the simple setup described above, check the docs for more info.