CGI Scripts with Nginx using SCGI
Using scgi_run with Nginx
Nginx is a great web server, but one thing it doesn't support is CGI scripts. Not all webapps need to be high-performance setups capable of hundreds or thousands of requests per second. Sometimes you just want something capable of handling a few requests now and then, and don't want to keep a long-running process going all the time just for that one webapp. How do you handle something like that under Nginx?
Well, it turns out you're going to have to have something running as a long-running external process to help Nginx out (because Nginx can't spawn processes itself). It just doesn't have to be dedicated to any one particular webapp. One way to go would be to setup another webserver that can do CGI scripts, and have Nginx proxy to that when need be.
Apache is one possibility, something like this:

But Apache's a fairly big program, has lots of features, a potentially complicated configuration. Kind of defeats the purpose of going to a lighter-weight program like Nginx. What else can we do?
Super-servers
Many Unix-type systems will have a super-server
available to launch daemons as need be when some network connection is
made. On BSD boxes it's typically inetd, MacOSX has launchd, Linux
distros often have xinetd or other choices available.
If we already have a super-server running on our box, why not setup Nginx to connect to that, and let the super-server take care of launching our CGI script? We just need one extra piece of the puzzle, something to read a web request over the socket Nginx opened up, setup the CGI environment, and execute the script.
Wait, that sounds like a web server - aren't we back to something like Apache again? No, it doesn't have to be anything nearly that complicated if we were to use the SCGI protocol, instead of HTTP.
SCGI
SCGI is a very simple protocol that's supported by Nginx and many other webservers. It's much much simpler than FastCGI, and maps pretty closely to the CGI specfication, with one minor difference to note...
In the CGI RFC, the response may contain an optional Status line, as in:
Status: 200 OKIn the SCGI protocol, the Status line is required, not optional.
Nginx will function with the Status line missing, but there'll be
warnings in your error log.
If you can alter your CGI scripts to include a Status line, or live with
warnings in logs, we have a way forward now.
scgi_run
I've got a C project on GitHub that implements this small piece of glue to turn a SCGI request into a CGI enviroment. The binary weighs in at around 8 to 12 Kilobytes after being stripped.
Basically, we're looking at a flow like this:
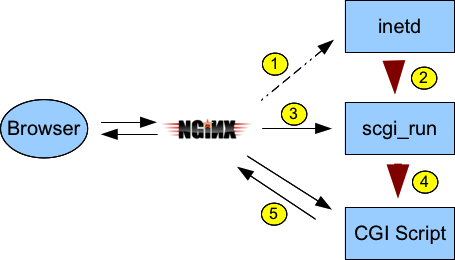
- Nginx connects to a socket listened to by inetd
- inetd spawns
scgi_run, with stdin and stdout wired to the accepted connection scgi_runreads SCGI request headers from stdin and sets up a CGI environmentscgi_runexecs CGI script (stdin and stdout are still connected to the socket to Nginx)- CGI script reads request body if necessary from stdin and writes response out through stdout.
A couple things to note here
- when we get to the final step, the CGI script is talking directly to Nginx - there's no buffering by any other applications like there would be in an Apache setup.
- scgi_run is no longer executing, it execed the CGI script so there's not another process hanging around waiting on anything.
- A super-server like inetd can typically be configured to run the handler under any userid you want, so you basically get SUEXEC-type functionality for free here.
The scgi_run code on GitHub operates in two modes:
- If argv[1] ends with a slash
/, then argv[1] is taken to be a directory name, and the program will look for theSCRIPT_FILENAMEpassed by Nginx in that directory. - Otherwise, argv[1] is taken as the path to a specific CGI script
(so
SCRIPT_FILENAMEis ignored), and any additional arguments are passed on to the CGI script.
Configuration
A simple setup looks something like this, assuming you've compiled scgi_run and have
the binary stored as /local/scgi_run
For FreeBSD inetd for example, you might add a line to /etc/inetd.conf like this:
:www:www:600:/var/run/scgi_localcgi.sock stream unix nowait/16 www /local/scgi_run /local/scgi_run /local/cgi-bin/Which causes inetd to listen to a Unix socket named
/var/run/scgi_localcgi.sock, and when a connection is made, it spawns
/local/scgi_run with argv[0] set to /local/scgi_run and argv[1] set
to /local/cgi-bin/. As a bonus, the socket ownership is set to www:www
and chmoded to 0600, which limits who can connect to it.
In Nginx, you might have something like:
location /local-cgi/ {
alias /local/cgi-bin/;
scgi_pass unix:/var/run/scgi_localcgi.sock;
include /usr/local/etc/nginx/scgi_params;
scgi_param SCRIPT_NAME $fastcgi_script_name;
scgi_param PATH_INFO $fastcgi_path_info;
scgi_param SCRIPT_FILENAME $request_filename;
}And then for a simple script, you might have /local/cgi-bin/hello.sh as
#!/bin/sh echo "Status: 200 OK" echo "Content-Type: text/plain" echo "" echo "Hello World"
That you would run by hitting http://localhost/local-cgi/hello.sh
Conclusion
So, with the help of a tiny 8KB binary, Nginx (or any other SCGI client)
with the help of a super-server like inetd can execute CGI scripts
(keeping in mind though the requirement for the Status line). It's a
fairly lightweight solution that may also be useful in embedded situations.
Enjoy, and go buy some harddrives to store your CGI scripts on, I hear SSDs are very nice. :)